Inhaltsverzeichnis
2. Verständnis von Blockchain und KI
2.2. Sicherheit und Unveränderlichkeit
3.1. Einführung zu Data Exchanges
3.1.2. Verantwortlichkeit und Sicherheit
3.1.3. Datenreinheit und User-Reputation
3.1.4. Automatisierte Zahlungskanäle
3.2. Data Exchanges als distribuierte Marktplätze
4. Anwendungsszenarien von Blockchain und KI
4.1. Blockchain-gestütztes Federated Learning – ein technologischer Deep-Dive
4.2. KI in der Gesundheitsforschung
4.3. Industrielle KI-Anwendung
1. Einleitung
Die Studie plädiert für den Aufbau eines europäischen KI-Ökosystems, das durch einen souveränen Datenmarktplatz und föderiertes Lernen gestützt wird. Ziel dieses Ansatzes ist es, Europas technologische Souveränität im Zeitalter der Künstlichen Intelligenz (KI) zu stärken, indem eine Blockchain-basierte Vision für „KI Made in Europe“ entwickelt wird. Im Mittelpunkt steht die Integration von Blockchain-Technologie und KI, um die Datenverarbeitung zu optimieren und neue Möglichkeiten zur effizienten Bewältigung der wachsenden Datenmengen zu schaffen. Ein wesentliches Potenzial der Blockchain liegt in ihrer Fähigkeit, einen gerechteren Zugang zu Daten zu ermöglichen und Beiträge innerhalb des Netzwerks produktiv zu synchronisieren. Das System baut dabei auf der existierenden dezentralen Dateninfrastruktur in Europa auf und sieht den föderierten Ansatz als Chance, die Europäische Diversität als globalen Wettbewerbsvorteil in der Entwicklung von KI Modellen zu verstehen.
Der Ansatz basiert auf drei Hauptkomponenten:
- Digitalisierung und Dateninfrastrukturen: Die Synergien von KI und Blockchain ermöglichen eine datenschutzkonforme Zusammenarbeit, die angesichts der zunehmenden Digitalisierung der Wirtschaft und steigender gesetzlicher Anforderungen an das Datenmanagement in der EU geschäftsentscheidend ist.
- Unternehmen: Besonders Start-ups sowie kleine und mittlere Unternehmen (KMUs) aus dem Mittelstand profitieren von den KI-Blockchain-Synergien. Aufgrund hoher Marktbarrieren und Datenschutzkosten konnten diese bisher weniger an den wirtschaftlichen Potenzialen der KI partizipieren als größere Konzerne.
- Datenmarktplätze: Durch den kombinierten Einsatz von Blockchain und KI können dezentrale digitale Infrastrukturen geschaffen werden. Diese ermöglichen es Individuen, Start-ups und Unternehmen, gemeinsam KI-Modelle zu trainieren und deren Ergebnisse zu nutzen oder Algorithmen zur Datenverarbeitung zu versenden, ohne die Inhalte ihrer Daten preiszugeben. Solche Marktplätze können sowohl von einzelnen als auch von unternehmerischen Akteuren genutzt werden und den Zugang zu wichtigen Datenquellen fördern.
2. Verständnis von Blockchain und KI
Mit historischen Wurzeln im Bereich der Kryptografie und Cypherpunk-Szene und aufgrund der weitreichenden Verbreitung durch die Erfindung des Bitcoin-Netzwerks durch die anonyme Erfinderin oder den anonymen Erfinder (oder die Personengruppe) Satoshi Nakamoto [1], hat die Blockchain-Technologie weitreichende Popularität erlangt. Im Kern lässt sich Blockchain als eine Technologie verstehen, die es ermöglicht, Konsens zwischen Akteuren herzustellen, die sich entweder nicht kennen oder einander nicht vertrauen können. Dies wird erreicht, indem eine distribuierte Netzwerkarchitektur jede Interaktion zwischen diesen Akteuren in einer unveränderlichen Datenbank aufzeichnet und somit effektiv die Funktion einer Vermittlerin oder eines Vermittlers ersetzt. Auf diese Weise wird eine Form des sozialen Austauschs ermöglicht, die oft als „vertrauensunabhängige Kommunikation“ bezeichnet wird. Wie bereits erwähnt, hat die vorangegangene Token Studie bereits einen wesentlichen Einblick in die technischen Spezifikationen von Blockchain-Technologien gegeben, weshalb dieser Bericht nicht darauf abzielen wird, Blockchain im Detail zu diskutieren. Nichtsdestotrotz wird auf die wesentlichen Merkmale der Blockchain-Technologie hingewiesen, die für das Thema dieses Berichts relevant sind. Im Folgenden wird eine kurze Einführung in jede dieser Eigenschaften gegeben:
2.1. Dezentralisierung
Ein Kernmerkmal im Design von (public ledger) Blockchains ist ihr distribuierter Ansatz in der Kommunikation (siehe Abbildung 1: Zentralisiertes vs. Dezentralisiertes Netzwerk). In diesem distribuierten System besteht die Blockchain aus einer Vielzahl von Nodes (Knotenpunkten), die Synchronität und stabilen Informationsaustausch im Netzwerk gewährleisten. Dadurch können Nutzerinnen und Nutzer direkt miteinander kommunizieren oder Blockchain- basierte Vermögenswerte versenden, was den in herkömmlichen Transaktionen üblichen Mittelsmann ersetzt [2]. Im Vergleich zu etablierten Online-Plattformarchitekturen wie von Google, Microsoft, Facebook usw. ermöglichen Blockchain-basierte Architekturen dabei einen egalitäreren Zugang zu Online-Infrastrukturen und bieten die Möglichkeit, Vermögenswerte zu tokenisieren. In der Folge können Nutzerinnen und Nutzer für ihre Aktivitäten bezahlt werden oder, wie im ursprünglichen Bitcoin-Anwendungsfall, das Netzwerk nutzen, um allgemein Zahlungen und Wertespeicherung anhand von Online-Währungen zu tätigen.
 Adaptiert von A.-L. Barabási, Linked: the new science of networks. Cambridge, Mass: Perseus Pub, 2002.
Adaptiert von A.-L. Barabási, Linked: the new science of networks. Cambridge, Mass: Perseus Pub, 2002.
2.2. Sicherheit und Unveränderlichkeit
Ursprünge in der Kryptographieforschung haben Blockchains mit hohen Sicherheitsstandards versehen. Jede Transaktion in der Blockchain wird dabei von allen Servern (Nodes) im Netzwerk verifiziert und gesichert. Anschließend werden Transaktionen und ihre Zeitstempel schreibgeschützt und dezentralisiert auf mehreren Nodes gespeichert, was den Dateneinträgen Unveränderlichkeit verleiht, sobald sie verifiziert sind. Da jede Node eine Kopie jeder Transaktion aufbewahrt und Änderungen nur zulässt, wenn eine Mehrheit der Nodes im (dezentralisierten) Netzwerk diese Änderung verzeichnet, gelten Blockchains als manipulationssicher [3]. Sie können folglich nur modifiziert werden, wenn eine Angreiferin oder ein Angreifer die Kontrolle über mehr als 50 Prozent der Nodes im Netzwerk erlangt.v Blockchains können auch auf effektive kryptographische Methoden bei ihren Transaktionen zurückgreifen, was eine weitere Ebene der Datensicherheit hinzufügt [4], [5]. Da jedoch viele beliebte Blockchains ihre Datenbanken mit öffentlichem Lesezugriff pflegen und jede Node-Betreiberin bzw. jeder Node-Betreiber normalerweise eine Kopie der gesamten Transaktionsdatenbank aufbewahrt, sind zusätzliche Modifikationen am System erforderlich, um vollständige Datenprivatsphäre für einzelne Nutzerinnen und Nutzer oder Anwendungsfälle zu gewährleisten [6]. Diese Vorbehalte werden in den nachfolgenden Kapiteln ausführlicher diskutiert.
2.3. Rückverfolgbarkeit
Einer der Kernvorteile der Verwendung von Blockchains zur Speicherung von Informationen ist, dass aufgrund ihres sequenziellen Ansatzes in der Informationsverarbeitung und -speicherung jedem Datenpunkt eine einzigartige ID zugewiesen wird. Diese Kennzeichnung ermöglicht unter anderem die Rückverfolgbarkeit und Überprüfbarkeit von Informationen, die auf der Blockchain gespeichert sind. So kann beispielsweise die Urheberin oder der Urheber (aka. Autorin oder Autor) eines bestimmten Datensatzes identifiziert und die Gültigkeit von Informationen sichergestellt werden. Gleichzeitig erlaubt das Merkmal der Rückverfolgbarkeit nachzuvollziehen, wie sich Informationen im Netzwerk verbreiten. Dies trägt dazu bei, Datenmissbrauch und -lecks schnell zu erkennen, so dass das Gesamtrisiko weitreichender Datenkompromittierung verringert werden kann.
2.4. Datenschutz
Während Blockchain in ihren Anfangstagen als Bewahrerin der Nutzeranonymität gepriesen wurde, haben Forschungen sowie jüngste Entwicklungen und Studien gezeigt, dass vollständige Privatsphäre und anonyme Nutzung von Blockchains in den meisten Fällen nicht umfassend gewährleistet sind [7]. Ein Grund hierfür ist, dass die oben beschriebenen Merkmale der Rückverfolgbarkeit und Transparenz in Datentransaktionen auch bedeuten, dass mit ausreichenden Daten und IT-Kenntnissen die Urheberin bzw. der Urheber einer bestimmten Transaktion zurückverfolgt und möglicherweise identifiziert werden kann. Um diesen Effekt abzumildern, stehen fortschrittliche Verschlüsselungsalgorithmen zur Verfügung, die jedoch, aufgrund ihrer eigenen inhärenten Komplexität, in diesem Bericht nicht vollständig diskutiert werden können. Für weiterführende Literatur, siehe [8], [9].
Eines der Kernprinzipien vieler technologisch fundierter Diskussionen über Blockchain ist ferner die Idee, dass ihre Möglichkeiten als Versuch gesehen werden können, ethische Verantwortlichkeit und möglicherweise sogar Fairness in digitale Infrastrukturen einzubringen. Bereits bei der Veröffentlichung des Bitcoin- Whitepapers war dieses ethische Prinzip ein zentraler Beweggrund Nakamotos [1]. Und trotz vieler Fälle von Betrug und Fehlverhalten im Bereich „Krypto“ – dem bisher bekanntesten und kapitalintensivsten Anwendungskontext der Blockchain – ist es für viele Befürworterinnen und Befürworter der Blockchain ein integraler Bestandteil ihres Enthusiasmus geworden, an dem Aufbau digitaler Infrastrukturen zu arbeiten, die zunehmend zugänglicher, egalitärer und fairer werden [10], [11]. In den vorangehenden Kapiteln wurden die technologischen Grundlagen der KI sowie mögliche Mängel übermäßig zentralisierter KI-Infrastrukturen diskutiert. Ziel der folgenden Abschnitte wird es sein, einen Überblick darüber zu geben, wie die vielversprechenden Möglichkeiten der Blockchain-Technologie helfen könnten, diese Risiken zu mildern.
3. Data Exchanges
3.1. Einführung zu Data Exchanges
Bislang hat dieser Bericht das Aufkommen von Blockchain und künstlicher Intelligenz als zwei Schlüsseltechnologien der Gesellschaften des frühen 21. Jahrhunderts erörtert. Dabei wurde die Bedeutung von KI betont, um die riesigen Datenmengen, welche digitale Infrastrukturen (darunter das Internet) täglich produzieren, wirksam zu verarbeiten und daraus Einsichten zu gewinnen, die sinnvoll und für Menschen lesbar sind. Gleichzeitig wurde hervorgehoben, wie Blockchain-Technologie entworfen wurde, um u.a. Defizite in den aktuell dominanten, eher zentralisierten digitalen Plattformarchitekturen zu adressieren. Auch die ethische Mission, die oft mit Blockchain verbunden wird, sobald eine eher technisch fokussierte Perspektive in Betracht gezogen wird, wurde betont. Letztendlich liegt die Relevanz der Verschmelzung von Blockchain und KI darin, dass Daten zu einem zunehmend zentralen Gut wirtschaftlicher Produktionszyklen werden. Gleichzeitig kann eine solche Konvergenz es ermöglichen, Daten für verschiedene Arten von Marktteilnehmern bereitzustellen, seien es Big-Tech-Unternehmen, Großkonzerne, KMUs oder alltägliche Internetnutzerinnen und Internetnutzer.
Die Stärke der Blockchain-Technologie liegt darin, dass sie es ermöglicht, Eigentum und Zugang zu ihrer Infrastruktur zu distribuieren und dies in Form von Transparenz, gleichem Zugang und Nachverfolgbarkeit für ihre Nutzerinnen und Nutzer. Diese Merkmale auf KIInfrastrukturen anzuwenden, könnte sich als eine wirksame Maßnahme erweisen, um digitale Infrastrukturen zu ermöglichen, die stärker mit den Wertvorstellungen der Europäischen Union übereinstimmen. Dabei würde der Schutz der Privatsphäre von Nutzerinnen und Nutzern gefördert [12] und gleichzeitig die Zusammenarbeit zwischen Akteuren innerhalb dieser neu entstehenden Datenräume sichergestellt [13].
Zeitgleich steht die aktuelle Datenwirtschaft vor zwei Herausforderungen beim Trainieren von Machine-Learning-Modellen: Einerseits existieren in vielen Branchen Daten in Form von isolierten Silos [14]. Diese Silos können zwischen Unternehmen, aber auch zwischen Abteilungen desselben Konzerns bestehen, da interner Wettbewerb Teams nicht immer dazu ermutigt, Daten zu teilen. Oder einfach, weil die Expertise und Ressourcen für die Einrichtung eines verbundenen Datensatzes nicht bereitgestellt werden können. Andererseits sehen sich Unternehmen mit wachsenden Anforderungen an die Einhaltung von Datenschutzvorschriften konfrontiert, was es zunehmend schwierig macht, kongruente Datenbanken zu erstellen und Machine-Learning-Modelle zu trainieren [14]. Datensilos sind ein Kernhindernis für die effektive Nutzung der Möglichkeiten von ML-Modellen. Wie zu Beginn des Berichts erwähnt wurde, sind Daten als Vermögensklasse im 21. Jahrhundert ebenso zentral wie es natürliche Ressourcen, etwa Öl, im 20. Jahrhundert waren. Es besteht jedoch ein Defizit darin, effektivere Lösungen zur Nutzung dieser neuen Vermögensklasse zu implementieren. Dabei bringen sie eine einzigartige Qualität mit sich: Während Öl jeweils nur in einer Einheit genutzt werden kann, können Daten unter Vielen geteilt werden [13], wodurch ihr positiver Gesamteffekt sogar verstärkt werden könnte.
Ein Weg, das Potenzial von Daten zu erschließen, während die Einhaltung des Datenschutzes und die Kontrolle über die eigenen Datensätze sichergestellt wird, könnte die Einrichtung sogenannter Data Exchanges sein. Data Exchanges könnten als kollaborativ genutzte (deutsche, europäische und auch global zugängliche) digitale Kontenpunkte operieren, die es Unternehmen und Einzelpersonen gleichermaßen ermöglichen würden, ihre Daten als Vermögenswerte auf einem offenen Datenmarkt anzubieten. Anschließend könnten sie gehandelt werden, um fortschrittliche KI-Modelle zu trainieren, wobei den Datengeberinnen und -gebern eine zuvor vereinbarte Form der Kompensation im Austausch garantiert wird. Amateur-Wetterstationen tragen bereits heute zur meteorologischen Vorhersage und genaueren Wetterprognosen bei. Beispielsweise besteht in den USA das Citizen Weather Observer-Programm aus mehr als 7.000 Stationen, die nach Eigenangaben eine Anzahl von 50.000 bis 70.000 Beobachtungen pro Stunde senden [15]. Nach vollzogener Qualitätskontrolle werden diese Daten dann von großen US-Institutionen genutzt, einschließlich des National Weather Service, des National Ocean Service und der NASA [15].
Während Amateurwetterstationen derzeit größtenteils selbstfinanziert betrieben werden, könnte die Einrichtung von Data Exchanges einen Anreiz für verschiedene Nutzerinnen und Nutzer und Anwendungsfälle bieten, um ihre Daten mit Dritten zu teilen. Dadurch könnten Dienste und KI-basierte Vorhersagen verbessert werden. Data Exchanges fungieren als Vermittler, die effektiv die Lücke zwischen Datenproduzentinnen und -produzenten sowie Datennutzerinnen und -nutzern schließen [16] und letztere fair für ihr Engagement entschädigen. Darüber hinaus könnte die Vertraulichkeit der bereitgestellten Daten gewährleistet werden, indem in einem dezentralisierten Machine-Learning-Ansatz lokal gespeicherte Daten eines Marktteilnehmers verwendet werden, um Modelle lokal zu trainieren. Anschließend würden die Ergebnisse dieser jeweiligen Teilmodelle dem Netzwerk übermittelt und ein neuer iterativer Konsens über ein größeres, globales Modell etabliert [14].
 Eigene Darstellung, basierend auf A. Qammar, A. Karim, H. Ning, und J. Ding, ‘Securing federated learning with blockchain: a systematic literature review’, Artif. Intell. Rev., vol. 56, no. 5, S. 3951–3985, 2023, doi: 10.1007/s10462-022-10271-9.
Eigene Darstellung, basierend auf A. Qammar, A. Karim, H. Ning, und J. Ding, ‘Securing federated learning with blockchain: a systematic literature review’, Artif. Intell. Rev., vol. 56, no. 5, S. 3951–3985, 2023, doi: 10.1007/s10462-022-10271-9.
Ein Vorteil dieser Architektur des sogenannten FL ist „die Entkopplung des [globalen] Modelltrainings
vom direkten Zugriff auf die rohen Trainingsdaten“ [17]. Datenschutz- und Sicherheitsrisiken werden hierdurch minimiert, da Datenübertragungen reduziert und sensible oder vertrauliche Daten ausschließlich lokal verarbeitet werden [17], [18]. Auf diese Weise können große KI-Modelle schrittweise trainiert werden, ohne den Inhalt lokaler Datensätze preiszugeben, wodurch die Risiken von Datenlecks oder Datenschutzverletzungen minimiert werden [17]. Die Verbindung des FL- Prozesses mit den einzigartigen Funktionen der Blockchain- Technologie (wie im vorherigen Abschnitt beschrieben) könnte europäischen Data
Exchanges folgende Vorteile bieten:
3.1.1. Datenurheberrechte
Die weit verbreitete Nutzung von generativen KI-Modellen (GenAI) hat Bedenken hinsichtlich des Urheberrechts geweckt und eine rechtliche Debatte darüber entfacht, ob Trainingsdaten ohne Bezugnahme auf deren Ursprung, wie Benutzerinnen und Benutzer, Autorinnen und Autoren oder anderen Formen der kreativen Urheberschaft, verwendet werden können. Ein bemerkenswertes Beispiel für diese Bedenken ist die Klage der New York Times gegen OpenAI und Microsoft wegen angeblicher Nutzung ihrer Inhalte ohne Befugnis [19]. Ähnliche Fälle wurden von der US-Autorengilde eingereicht und waren einer der Haupttreiber für die kürzlichen Streiks der Writers Guild of America (welche Drehbuchautorinnen und -autoren vertritt) in der US-Filmindustrie. Alle drei genannten Parteien argumentieren für eine Verletzung des Urheberrechts, die bei KI-Trainingsprogrammen stattgefunden hat, und fordern Mittel zur Entschädigung (z. B. eine Nutzungsgebühr), sobald ihre Inhalte bei der Entwicklung von KI-Modellen verwendet werden. Diese Fälle weisen auf zwei aktuelle Probleme hin: Erstens gibt es bisher kein umfassendes Verzeichnis, um den Ursprung der zahlreichen Datenquellen nachzuverfolgen, die in das Training fortgeschrittener KI-Modelle einfließen. Und zweitens fehlt es an allgemein anerkannten rechtlichen Rahmenbedingungen und Infrastrukturen, die einen legitimen Zugang und eine gerechte Entschädigung für die Nutzung persönlicher oder unternehmensbezogener Datensätze ermöglichen. Um diese Probleme zu mildern, könnte ein auf Blockchain basierender Datenmarktplatz die Datenurheberschaft nachweisen und eine faire und automatisierte Monetarisierung sowie das Tracking von KI-Trainingsdaten ermöglichen. So kann in der Folge eine transparente und offen zugängliche Infrastruktur für die KI-Entwicklung etabliert werden. Ähnlich wie heute Stockbilder im Internet gekauft werden, könnten Data Exchanges beispielsweise den Erwerb von lizenziertem Zugang zu privaten und unternehmensbezogenen Datensätzen ermöglichen und im Gegenzug Datengeberinnen und -geber fair entschädigen.
Gleichzeitig könnten Datenproduzentinnen und -produzenten mithilfe von Blockchain-basierten Datenmarktplätzen ihre Urheberschaft mittels eindeutiger Identifikatoren registrieren und so einen klar definierten, digitalen Beleg ihres Eigentums generieren. Im Dezember 2023 setzte der in den USA ansässige Mediendienst Fox News bereits sein Verifizierungstool „Verify“ [20], [21] ein, das kryptographisches Hashing und digitale Signaturen nutzt, um die Originalität seiner Inhalte zu authentifizieren. Hauptziel ist es, jeder Endnutzerin und jedem Endnutzer zu ermöglichen, den Ursprung von Inhalten als von Fox News produziert zu erkennen. Doch Modelle wie das Beispiel von Fox News könnten leicht angepasst werden, um die Echtheit verschiedenster Daten und Inhalten zu gewährleisten. Während bis heute noch kein Entschädigungsmechanismus für das Training von KI existiert, könnte diese bereits gehashte Datenbank jedoch problemlos in einem gegebenen Data Exchange zu Trainingszwecken integriert werden.
3.1.2. Verantwortlichkeit und Sicherheit
Wie zuvor beschrieben, verbinden Blockchains Daten über Blöcke und sichern diese kryptographisch [1], [22]. Folglich können Modifikationen durch bösartige Akteure leicht erkannt werden [18]. In diesem Sinne bietet das System erweiterte Sicherheit gegen externe Angriffe und gewährleistet, dass die bereits trainierten Modelle ihre Gültigkeit behalten. Besonders in Zeiten weltweit zunehmender Hackerangriffe [7] fügt die Verbesserung von Datenpipelines durch Blockchain-Verifizierung zusätzliche Sicherheit und Schutz für laufende Machine-Learning-Dienste hinzu. Beispielsweise könnte die Verbindung von Blockchain und KI erweiterte Sicherheit und Schutz vor Hackerangriffen für Netzwerke bieten, die autonome Fahrzeuge steuern und verwalten [23]. In diesem Szenario kann die Kombination beider Technologien helfen, „unerwünschte Datenmodifikationen in Fahrzeugnetzwerken“ [23] zu verhindern und damit die allgemeine Fahrsicherheit zu erhöhen. Darüber hinaus können durch kryptographische Eigenschaften der Blockchain geschützte Daten angepasst werden, um dem EU-Datenschutzrecht zu entsprechen und sicher in einem föderierten Umfeld geteilt zu werden [24]. Eine mögliche Anwendung wäre die Verbesserung des KI-Algorithmus zur Bedrohungserkennung und um die Gesamtsicherheitsleistung von Fahrzeugen zu erhöhen.
3.1.3. Datenreinheit und User-Reputation
Wie zuvor diskutiert, profitieren Machine-Learning- Modelle von hochwertigen und vielfältigen Daten, die in ihr Training einfließen. Da man bei Blockchains die Urheberin bzw. den Urheber eines bestimmten Datensatzes zurückverfolgen kann, können Autorinnen und Autoren als auch ihre Daten auf einem entsprechenden Datenmarktplatz bewertet werden [25]. Dies ermöglicht die Etablierung eines nachvollziehbaren und verifizierbaren Reputationssystems in einem distribuierten Umfeld. Beispielsweise könnte, im Kontext des zuvor erwähnten Hobbyisten- Netzwerk zur Bereitstellung von Wetterdaten, die Herkunft und der Standort eines Messgeräts (zum Beispiel eine Webcam) durch die Originalhersteller als auch die aktuelle Besitzerin bzw. den aktuellen Besitzer authentifiziert werden, um die Echtheit der generierten Daten zu gewährleisten. Basierend auf der verwendeten Hardware und der Reputation der Nutzerinnen und Nutzer könnten deren lokale Beiträge zum globalen Modell effektiv bewertet werden. Durch diese Konfiguration könnten Teilnehmende ohne die Notwendigkeit der Kenntnis voneinander (oder auch des Vertrauens zueinander) Daten effektiv handeln und zu fortgeschrittener Entwicklung einer Datenökonomie beitragen [26], [27].
3.1.4. Automatisierte Zahlungskanäle
Als zusätzlicher Vorteil könnten Daten- und Zahlungstransaktionen zwischen Marktteilnehmerinnen und -teilnehmern vollautomatisch erfolgen. Trainingsquellen könnten dabei öffentliche Infrastrukturen, IoT-Geräte, Sensoren industrieller Maschinen oder sogar persönliche Smartphones umfassen. Viele dieser Geräte tätigen Transaktionen, die durch ihre geringe Größe und hohe Frequenz gekennzeichnet sind. Ein solches Umfeld ermöglicht den Einsatz von automatisierten Zahlungskanälen, die in der Lage sind, Echtzeit-Transaktionen abzuwickeln. Dies bietet einen Vorteil gegenüber traditionellen Verifizierungs- und Abwicklungsmethoden durch Dritte, wie Banküberweisungen oder SWIFT, welche Mikrotransaktionen aufgrund ihres zeitaufwändigen und kostspieligen Charakters nicht ähnlich effizient abwickeln können [11]. Als Alternative würden Blockchain-basierte Data Exchanges mit sofortigen und automatisierten Zahlungsmechanismen ausgestattet, die direkte finanzielle Transaktionen zwischen Kaufenden und Verkaufenden erleichtern. Die Verwendung digitaler Währungen, wie beispielsweise eines digitalen Euros, wäre eine Möglichkeit, die Zuverlässigkeit von Austauschdynamiken zu optimieren. Denn sie ermöglichen Dateninhabern, ihre Vermögenswerte zu monetarisieren, wobei eine verlässliche und nachprüfbare Kompensation sowie ein reibungsloses und sicheres Transaktionserlebnis innerhalb von Data Exchanges gewährleistet wird.
3.2. Data Exchanges als distribuierte Marktplätze
Wie die obigen Abschnitte gezeigt haben, kann die Verbindung von Blockchain und KI genutzt werden, um eine effektive Marktplatzumgebung für Datensätze einer distribuierten Gruppe von Teilnehmenden zu etablieren. Datenmarktplätze könnten als Vermittler fungieren und so die Lücke zwischen Datenproduzierenden und Nutzenden effektiv überbrücken [16]. Zudem könnten Marktteilnehmerinnen und Marktteilnehmer eine Vielzahl von automatisierten Mitteln nutzen – von öffentlichen Infrastrukturvorrichtungen und Sensoren für Produktionsmaschinen bis hin zu persönlichen Smartphones – um damit eine Quelle des passiven Einkommens zu generieren. Besonders profitieren könnten datenaffine Einzelpersonen sowie Unternehmen datenintensiver Sektoren wie dem Maschinenbau, der Fertigung und Produktion oder IoT-Betreiber.
Gleichzeitig könnten Internetnutzerinnen und -nutzer diese Infrastruktur verwenden, um wahrhaftige Eigentümer an ihren digitalen Daten zu werden oder auch um eine faire Entschädigung für die Weitergabe ihres Profils zur Verarbeitung von Dritten (z. B. Unternehmen) zu erhalten, die umfangreichere Kundenkenntnisse erlangen möchten. Darüber hinaus könnten Datenbörsen auch eine unterstützende Funktion haben, um sicherere Formen der öffentlichen Informationsbeschaffung zu etablieren: Erstellerinnen und Ersteller von Inhalten, wie Zeitungsverlage oder Medienhäuser, könnten in die Lage versetzt werden, ihre Veröffentlichungen als Eigentum zu markieren und so die faktische Richtigkeit der online bereitgestellten Inhalte über ihre Reputation zu gewährleisten. Zusätzlich könnten Nutzerinnen und Nutzer ein gegebenes Reputationssystem verwenden, um die Authentizität der Berichte zu bestätigen. Besonders in Zeiten zunehmender Falschinformationen online, könnten Datenverifizierungsstellen für Medien eine wirksame Gegenmaßnahme bieten und eine weitere Unterscheidungs- und Vertrauensebene zu öffentlichen Medien hinzufügen [21], [28].
Letztendlich könnte die Implementierung distribuierter Data Exchanges eine Grundlage für ein datengesteuertes, wettbewerbsfähiges Marktumfeld schaffen, in dem Unternehmen innovativ wirken können, während die eigene Datensouveränität gewahrt wird. Eine derartige Infrastruktur ermöglicht die Entwicklung neuer Geräte- oder Webanwendungen sowie Datenverarbeitungs- und Machine-Learning-Services. Diese können mit fortschrittlicher Ausgabegenauigkeit für spezifische Marktnischen maßgeschneidert werden. Die Einrichtung eines Blockchain-basierten Datenmarktplatzes könnte damit erhebliche Vorteile für die lokale Wirtschaft bieten, das Wettbewerbsumfeld verbessern und eine vielfältige Datenökologie fördern, was letztlich zu einem lebendigen europäischen Datenökosystem beitragen könnte. Abbildung 2 zeigt eine stark vereinfachte Version, wie Datenbörsen funktionieren könnten. Jede Phase der Datentransaktion wird in der nachfolgenden Zusammenfassung illustriert. Der anschließende Abschnitt wird dann einen tieferen Einblick geben, wie distribuierte Machine-Learning-Infrastrukturen funktionieren könnten und zusätzliche Nutzungsfälle mit hohem wirtschaftlichem Potenzial aufzeigen.
- Angebotseinleitung: In dieser grundlegenden Phase generieren die Teilnehmerinnen und Teilnehmer, sei es als Datenanbietende oder -erwerbende, Angebote, die auf der Blockchain aufgezeichnet werden, was Transparenz und Unveränderlichkeit gewährleistet. Diese Angebote durchlaufen strenge Validierungsprozesse, die ihre Echtheit und Zuverlässigkeit sicherstellen. Um eine automatisierte Abwicklung zu erleichtern, werden Datenanfragen mit entsprechenden Zahlungen in digitaler Währung verbunden und treuhänderisch gehalten, um die Transaktionsvollendung bei erfolgreicher Datenlieferung zu garantieren.
- Partnervermittlung: Angebote werden abgeglichen, wenn die Teilnehmerinnen und Teilnehmer einen Konsens erreichen, was direkt oder durch Gegenangebote, die die Bedingungen der Zusammenarbeit verfeinern, geschehen kann. Bei Einigung werden alle erforderlichen Informationen sicher verarbeitet; beispielsweise würde dies im Kontext des föderierten Lernens ein Aktualisieren des globalen Modells über dezentrale Modelliterationen beinhalten.
- Datenverarbeitung (inkl. Training): Abhängig vom Typ des Datenabkommens führt die oder der Datenbesitzende entweder das lokalemTraining des KI-Algorithmus durch oder initiiert die Transaktion ihrer oder seiner angebotenen Daten. Die Transaktion gipfelt im direkten Austausch der Daten von Datenbesitzenden zu Datenkäufern.
- Vertrags- und Zahlungsabwicklung: Nach der Lieferung durchlaufen die erhaltenen Daten einen Verifizierungsprozess, um ihre Integrität und die Einhaltung der Vertragsbedingungen zu bestätigen. Sollten Unstimmigkeiten auftreten, wird ein Streitbeilegungsmechanismus aktiviert. Nach einer zufriedenstellenden Lösung wird die Zahlung aus dem Treuhandkonto freigegeben und automatisch verarbeitet. Zusätzlich werden Transaktionsdetails und Teilnehmendenrückmeldungen in ein umfassendes Reputationssystem eingebettet, was zu zukünftigem Vertrauen und der Einhaltung von Verantwortlichkeiten
beiträgt.
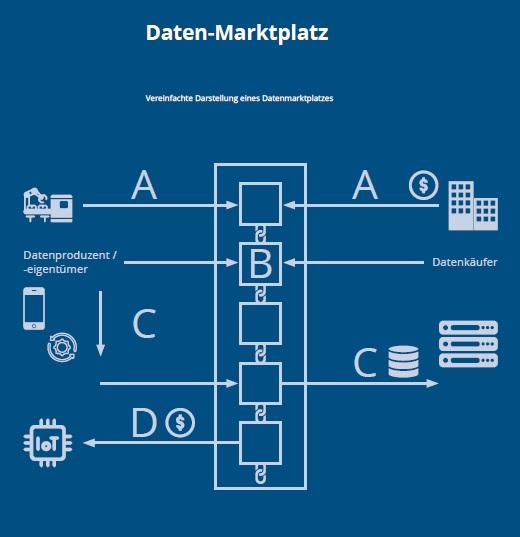 Eigene Darstellung, basierend auf S. Heister und K. Yuthas, ‘How Blockchain and AI Enable Personal Data Privacy and Support Cybersecurity’, in Blockchain Potential in AI, T. M. Fernández-Caramés and P. Fraga-Lamas, Eds., IntechOpen, 2022. doi: 10.5772/intechopen.96999.
Eigene Darstellung, basierend auf S. Heister und K. Yuthas, ‘How Blockchain and AI Enable Personal Data Privacy and Support Cybersecurity’, in Blockchain Potential in AI, T. M. Fernández-Caramés and P. Fraga-Lamas, Eds., IntechOpen, 2022. doi: 10.5772/intechopen.96999.
4. Anwendungsszenarien von Blockchain und KI
4.1. Blockchain-gestütztes Federated Learning – ein technologischer Deep-Dive
4.2. KI in der Gesundheitsforschung
Die Daten des Gesundheitswesens unterliegen strengen Datenschutzbestimmungen, sodass die zentralisierte Datenverarbeitung und das KI-Training ethischen und rechtlichen Einschränkungen unterliegen. Um die Vorteile von Big Data im Gesundheitswesen zu fördern, wurden umfangreiche Forschungsarbeiten zu
datenschutzfreundlichen FL-Ansätzen für die Entwicklung von KI im Gesundheitswesen durchgeführt [29], [30], [31]. Obwohl es sich um eine vielversprechende Technologie handelt, ist eine KI-basierte Scan-Software in den häufig vorkommenden Datensilos des Gesundheitswesens schwer zu entwickeln [32]. Daher ermöglicht FL die lokale Nutzung privater Daten, um einen KI-Algorithmus zu trainieren, z. B. bei der Erkennung von Hirntumoren [30]. Ein Blockchain-basiertes FL-Netzwerk könnte ein vielversprechender Weg sein, um die Zusammenarbeit zwischen verschiedenen Gesundheitseinrichtungen wie öffentlichen Krankenhäusern, Forschungsinstituten und Universitäten beim Training eines KI-Erkennungssystems zu ermöglichen. In Folge würde die Arbeit vor Ort unterstützt und beschleunigt oder bestehende Behandlungsverfahren verbessert werden. Gerade im Gesundheitswesen sind solche Implementierungen jedoch mit Vorsicht zu genießen. Wie das folgende Kapitel erörtert, kann ein betrügerischer Angriff auf das globale Modell trotz datenschutzfreundlicher Methoden wie Differential Privacy immer noch Informationen über die Trainingsdaten preisgeben [33]. Vor allem bei hochsensiblen personenbezogenen Daten müssen diese Bedenken berücksichtigt und ausgeräumt werden, bevor eine FL-Architektur für Gesundheitsdaten wirksam und unter Berücksichtigung ethischer Standards eingeführt werden kann.
4.3. Industrielle KI-Anwendung
Für die Anwendung von FL in der Industrie gibt es im Wesentlichen zwei Möglichkeiten:
(A) Große Industrieunternehmen könnten FLAnsätze in Projekte integrieren, um einen KI-Algorithmus zu trainieren, der auf Performancedaten von Kundinnen und Kunden ohne Verletzung der Privatsphäre aufbaut. Ein Pilotprojekt für diese Implementierung wurde in Deutschland vom Fraunhofer IPA und der Lorch AG, einem Hersteller von Schweißmaschinen, durchgeführt. Ein vielversprechender Effekt dieser Zusammenarbeit war, dass das föderierte Training von mehreren sich in Betrieb befindenden Schweißmaschinen zu einem KI-Modell führte, das in der Lage ist, eine Schweißmaschine proaktiv abzuschalten, wenn eine Mitarbeiterin oder ein Mitarbeiter gerade dabei ist, einen potenziell gefährlichen Fehler zu begehen [34]. Solche Anwendungen von FL könnten besonders für Deutschlands kleine und mittelständische Unternehmen relevant sein und dazu beitragen, die globale Wettbewerbsfähigkeit für KI-gestützte Implementierungsszenarien zu verbessern. Unternehmen könnten lokales KI-Training nutzen, um gemeinsame globale Modelle zu entwickeln, die sich auf eine hohe maschinelle Leistungsgenauigkeit stützen, und sich gleichzeitig auf Nischenanwendungen spezialisieren, die auf individuelle Geschäftsfälle zugeschnitten sind. Durch ein FL-Szenario könnte Deutschlands derzeitiger Wettbewerbsvorteil, ein größeres Cluster von weltweit führenden Industrie- und Fertigungsunternehmen zu haben, die Möglichkeit bieten, ein Netzwerk von KI-Marktführern in Industrie- und Fertigungsszenarien aufzubauen und einen künftigen Wettbewerbsvorteil darstellen.
(B) In einem zweiten Szenario könnten industrielle Hersteller FL als Teil ihrer länderübergreifenden Maschineninfrastruktur implementieren und so ein kollaboratives Training für ihre Maschinen in Deutschland und im Ausland unter Berücksichtigung der lokalen Datenschutzgesetze schaffen. In einem Projekt mit Siemens hat das Start-up Katulu eine FL-Infrastruktur für die Verbesserung der automatischen optischen Inspektionssysteme in den Siemens-Werken in Erlangen entwickelt [35]. Nach Angaben von Katulu bildet das erfolgreich implementierte FL-System die Grundlage für einen breiteren Rollout in weiteren Siemens-Werken, auch in China.
4.4. Smart City und IoT-KI
Maschinen, die in der städtischen Infrastruktur eingesetzt werden, produzieren zunehmend große Datenmengen, die in ihrer Summe das Internet der Dinge bilden. Diese Kommunikationsnetze sind für den Einsatz intelligenter Geräte unumgänglich. Die Nutzung des autonomen Fahrens von Fahrzeugen in der Stadt basiert beispielsweise auf dem Zugang zu großen Datensätzen der lokalen Umgebung und der anschließenden schnellen und intelligenten Analyse. Durch den Einsatz von KI können wichtige Berechnungen durchgeführt werden, z. B. zur Vorhersage des Verkehrsflusses [36]. Im Pilotprojekt „Heat“, das 2021 in der Stadt Hamburg durchgeführt wurde, wurden autonome Kleinbusse erfolgreich eingesetzt, die ein umfassendes KI- und IoT-Netzwerk nutzten, welches Echtzeitdaten aus der Umgebung ableitet [37]. Das vom Bundesministerium für Digitales und Verkehr geförderte Nachfolgeprojekt „ALIKE“ soll ab 2024 öffentlich zugängliche, autonome Kleinbusse in Hamburg bereitstellen [38]. Diese Fallstudien zeigen, dass gut trainierte KI-Algorithmen und der Zugang zu Daten ein wichtiger Faktor sind, um das autonome Fahren voranzubringen. Dateninseln und geschlossene KI-Trainingssysteme könnten jedoch die Entwicklung erschweren und die Herstellung von Transparenz zwischen den Beteiligten verkomplizieren, z. B. im Falle von Unfällen oder ähnlichen Ereignissen, die eine rechtliche Klärung erfordern. Die Implementierung eines FL-Netzwerks, das auf distribuierten Eigentumsverhältnissen basiert, könnte die Entwicklung transparenter und effektiver Algorithmen für das autonome Fahren beschleunigen. Mit einem datenschutzfreundlichen Zugang zu IoT-Daten, die für das Training von KI-Algorithmen genutzt werden können und gleichzeitig die Zusammenarbeit einer Vielzahl von Akteuren fördern, unterstützt Blockchain die kollaborative Smart-City-Entwicklung in einem egalitären Umfeld für alle Beteiligten und fördert Anreize für den freien Markt.
4.5. Mobile KI-Anwendungen
FL kann auf mobilen Geräten angewandt werden, um auf Trainingsdaten zuzugreifen, die normalerweise zu klein wären, um für ein effektives Training in Frage zu kommen [39]. Um einen erweiterten Zugang zu Trainingsdaten zu ermöglichen, haben die Autoren Bonawitz et al. [39] ein FL-System entwickelt, das einer Vielzahl von mobilen Geräten ermöglicht, dem Netzwerk beizutreten und an Trainingsrunden teilzunehmen. Dies kann z. B. bei E Commerce-Empfehlungsalgorithmen nützlich sein, die häufig in der Cloud gespeicherte, aber sensible Nutzerdaten verwenden, welche möglicherweise gegen das Datenschutzrecht verstoßen. In Anbetracht dieses Szenarios haben Forschende erfolgreich die Anwendung eines datenschutzfreundlichen FL-Systems für Alibaba und Taobao getestet, das On-Device- Daten nutzt [40]. Solche Innovationen könnten für deutsche E-Commerce-Plattformen wie Zalando und AboutYou alternative Infrastrukturen bieten. Außerdem werden diese Ansätze durch jüngste Fortschritte wie die FL-Anwendung PockEngine, die die erforderliche Rechenleistung für effizientes KI-fine-tuning erheblich reduzieren, zunehmend realisierbar [41].
4.6. Vertrauenswürdige KI
Der kürzlich erlassene EU AI-Act fordert klare Datenverwaltung, Aufzeichnungspflicht, Transparenz und Zugangskontrolle für KI [12]. Um diese neue Verordnung zu erfüllen, könnte Blockchain dabei helfen, eine Überprüfbarkeit, Transparenz und Rückverfolgbarkeit für KIModelle zu schaffen [12]. In diesem Bericht wurden mehrere mögliche Szenarien für diese Funktionen erörtert, sind aber nicht auf das Thema der Überprüfbarkeit eingegangen. Wie bereits erwähnt, ist es schwierig, wenn nicht gar unmöglich, die interne Dynamik von KI-Modellen, die auf neuronalen Netzen basieren, vollständig zu verstehen, weshalb die genauen Entscheidungsprozesse fortgeschrittener KI-Modelle bis heute nicht vollständig rückverfolgt werden können. Mit zunehmender Modellgröße und damit zunehmender Modellkomplexität wird sich dieser Trend voraussichtlich fortsetzen, sodass es für menschliche Beobachter immer schwieriger wird, einen vollständigen Einblick in die Art und Weise zu gewinnen, wie ein bestimmtes KI-Modell zu einer bestimmten Entscheidung oder Vorhersage gekommen ist. Ähnlich wie Github die Nachverfolgung von Code-Änderungen über sogenannte „Commits“ ermöglicht, könnte die Blockchain jedoch die Erstellung von Prüfpfaden ermöglichen, um Änderungen, Erweiterungen oder Datenquellen, die in ein bestimmtes Modell eingeflossen sind, nachzuverfolgen - und diese Aufzeichnungen als unveränderlich zu speichern, solange die Blockchain existiert [42]. Dieser Ansatz bietet zwar keinen umfassenden Einblick in das KI-System, könnte aber Prüfenden und Regulierungsbehörden eine erste Orientierung bieten, um die Blackbox-Dynamik der Entscheidungsfindung eines bestimmten Modells zu verstehen. Zukünftige Forschung sollte sich damit befassen, wie dieser Ansatz sicher implementiert und ob andere Methoden produktiv eingesetzt werden können, um zukünftig sicherere und besser überprüfbare KI-Systeme zu entwickeln.
5. Fazit
Lesen Sie hier das Fazit und die komplette Studie als PDF.
[1] S. Nakamoto, ‘Bitcoin: A Peer-to-Peer Electronic Cash System’. 2008. Letzter Zugriff 2. Februar 2023 [Online]. https://bitcoin.org/bitcoin.pdf.
[2] S. Ding und C. Hu, ‘Survey on the Convergence of Machine Learning and Blockchain’, 2022, doi: 10.48550/ARXIV.2201.00976.
[3] H. Taherdoost, ‘Blockchain Technology and Artificial Intelligence Together: A Critical Review on Applications’, Appl. Sci., vol. 12, no. 24, S. 12948, Dez. 2022, doi: 10.3390/app122412948.
[4] X. Zhu, H. Li, und Y. Yu, ‘Blockchain-Based Privacy Preserving Deep Learning’, in Information Security and Cryptology, vol. 11449, F. Guo, X. Huang, and M. Yung, Eds., in Lecture Notes in Computer Science, vol. 11449., Cham: Springer International Publishing, 2019, S. 370–383. doi: 10.1007/978-3-030-14234-6_20.
[5] S. Heister und K. Yuthas, ‘How Blockchain and AI Enable Personal Data Privacy and Support Cybersecurity’, in Blockchain Potential in AI, T. M. Fernández-Caramés and P. Fraga-Lamas, Eds., IntechOpen, 2022. doi: 10.5772/intechopen.96999.
[6] A. Pentland, J. Werner, und C. Bishop, ‘Blockchain+AI+Human: Whitepaper and Invitation’. The MIT Trust::Data Consortium for blockchain+AI research, 2021. Letzter Zugriff 2. Februar 2023 [Online]. https://connection.mit.edu/sites/default/files/publication-pdfs/blockchain%2BAI%2BHumans.pdf.
[7] S. Heister und K. Yuthas, ‘How Blockchain and AI Enable Personal Data Privacy and Support Cybersecurity’, in Blockchain Potential in AI, T. M. Fernández-Caramés and P. Fraga-Lamas, Eds., IntechOpen, 2022. doi: 10.5772/intechopen.96999.
[8] X. Sun, F. R. Yu, P. Zhang, Z. Sun, W. Xie, und X. Peng, ‘A Survey on Zero-Knowledge Proof in Blockchain’, IEEE Netw., vol. 35, no. 4, S. 198–205, Jul. 2021, doi: 10.1109/ MNET.011.2000473.
[9] A. Acar, H. Aksu, A. S. Uluagac, und M. Conti, ‘A Survey on Homomorphic Encryption Schemes: Theory and Implementation’, ACM Comput. Surv., vol. 51, no. 4, pp. 1–35, Jul. 2019, doi: 10.1145/3214303.
[10] V. Buterin, ‘The Meaning of Decentralization’, Medium. Accessed: Feb. 27, 2024. [Online].
https://medium.com/@VitalikButerin/the-meaning-of-decentralization-a0c92b76a274.
[11] A. M. Antonopoulos, The internet of money: a collection of talks. Volume 1. Vereinigte
Staaten von America: Merkle Bloom LLC, 2016.
[12] S. Ramos und J. Ellul, ‘Blockchain for Artificial Intelligence (AI): enhancing compliance with the EU AI Act through distributed ledger technology. A cybersecurity perspective’, Int. Cybersecurity Law Rev., vol. 5, no. 1, S. 1–20, Mar. 2024, doi: 10.1365/s43439-023-00107-9.
[13] A. Pentland, A. Pentland, A. Lipton, und T. Hardjono, Building the new economy: data as capital. Cambridge, Massachusetts; London, England: The MIT Press, 2021.
[14] Y. Cheng, Y. Liu, T. Chen, und Q. Yang, ‘Federated learning for privacy-preserving AI’, Commun. ACM, vol. 63, no. 12, S. 33–36, Nov. 2020, doi: 10.1145/3387107.
[15] CWOP, ‘Citizen Weather Observer Program’, Citizen Weather Observer Program. Letzter Zugriff 27. Februar 2024. [Online]. http://wxqa.com/.
[16] L. D. Nguyen, S. R. Pandey, S. Beatriz, A. Broering, und P. Popovski, ‘A Marketplace for Trading AI Models based on Blockchain and Incentives for IoT Data’, no. arXiv:2112.02870. arXiv, Dec. 06, 2021. Accessed: Jan. 29, 2024. [Online]. http://arxiv.org/abs/2112.02870.
[17] H. B. McMahan, E. Moore, D. Ramage, S. Hampson, und B. A. y Arcas, ‘Communication-Efficient Learning of Deep Networks from Decentralized Data’, 2016, doi: 10.48550/ARXIV.1602.05629.
[18] A. Qammar, A. Karim, H. Ning, und J. Ding, ‘Securing federated learning with blockchain:a systematic literature review’, Artif. Intell. Rev., vol. 56, no. 5, S. 3951–3985, 2023, doi:10.1007/s10462-022-10271-9.
[19] M. M. Grynbaum und R. Mac, ‘New York Times Sues OpenAI and Microsoft Over Use of Copyrighted Work - The New York Times’, The New York Times, New York, Dez. 27, 2023. Letzter Zugriff 27. Februar 2024 [Online]. https://www.nytimes.com/2023/12/27/business/media/new-york-times-open-ai-microsoft-lawsuit.html.
[20] F. Corporation, ‘Verify tool’, verify.fox. Letzter Zugriff 27. Februar 2024 [Online]. https://www.verify.fox.
[21] Polygon Labs, ‘Fox Corporation Taps Polygon PoS to Power Verify, an Open Protocol for Content and Image Verification’. Letzter Zugriff 27. Februar 2024 [Online]. https://polygon.technology/blog/fox-corporation-taps-polygon-pos-to-power-verify-an-open-protocol-forcontent-and-image-verification.
[22] T. Laurence, Blockchain for Dummies, 3rd ed. Indianapolis: John Wiley & Sons Inc, 2023.
[23] G. Bendiab, A. Hameurlaine, G. Germanos, N. Kolokotronis, und S. Shiaeles, ‘Autonomous Vehicles Security: Challenges and Solutions Using Blockchain and Artificial Intelligence’, IEEE Trans. Intell. Transp. Syst., vol. 24, no. 4, S..3614–3637, Apr. 2023, doi: 10.1109/TITS.2023.3236274.
[24] A. Giannaros et al., ‘Autonomous Vehicles: Sophisticated Attacks, Safety Issues, Challenges, Open Topics, Blockchain, and Future Directions’, J. Cybersecurity Priv., vol. 3, no. 3, S.. 493–543, Aug. 2023, doi:10.3390/jcp3030025.
[25] A. Dixit, A. Singh, Y. Rahulamathavan, und M. Rajarajan, ‘FAST DATA: A Fair, Secure, and Trusted Decentralized IIoT Data Marketplace Enabled by Blockchain’, IEEE Internet Things J., vol. 10, no. 4, Art. no. 4, Feb. 2023, doi: 10.1109/JIOT.2021.3120640.
[26] Z. Zhou, C. Guo, X. Zhang, R. Wang, L. Zhang, und M. Imran, ‘A Blockchain-based Data Sharing Marketplace with a Federated Learning Use Case’, in 2023 IEEE International Conference on Blockchain and Cryptocurrency (ICBC), Dubai, United Arab Emirates: IEEE, May 2023, S.. 1041–1044. doi: 10.1109/ICBC56567.2023.10174981.
[27] B. Eom, S. Lim, Y.-H. Suh, S. Woo, und C. Park, ‘Federated Learning Using Blockchain-based Marketplace’, in 2023 Fourteenth International Conference on Ubiquitous and Future Networks (ICUFN), Paris, Frankreich: IEEE, Jul. 2023, S. 795–797. doi: 10.1109/ICUFN57995.2023.10199626.
[28] X. Wang, H. Xie, S. Ji, L. Liu, und D. Huang, ‘Blockchain-based fake news traceability and verification mechanism’, Heliyon, vol. 9, no. 7, S. e17084, Jul. 2023, doi: 10.1016/j.heliyon.2023.e17084.
[29] R. S. Antunes, C. André Da Costa, A. Küderle, I. A. Yari, und B. Eskofier, ‘Federated Learning for Healthcare: Systematic Review and Architecture Proposal’, ACM Trans. Intell. Syst. Technol., vol. 13, no. 4, Art. no. 4, Aug. 2022, doi: 10.1145/3501813.
[30] W. Li et al., ‘Privacy-preserving Federated Brain Tumour Segmentation’, no. arXiv:1910.00962. arXiv, Oct. 02, 2019. Letzter Zugriff 28. Januar 2024 [Online]. http://arxiv. org/abs/1910.00962.
[31] D. C. Nguyen et al., ‘Federated Learning for Smart Healthcare: A Survey’, ACM Comput. Surv., vol. 55, no. 3, Art. no. 3, März. 2023, doi: 10.1145/3501296.
[32] R. O. Ogundokun, S. Misra, R. Maskeliunas, und R. Damasevicius, ‘A Review on Federated Learning and Machine Learning Approaches: Categorization, Application Areas, and Blockchain Technology’, Information, vol. 13, no. 5, S. 263, May 2022, doi: 10.3390/info13050263.
[33] P. Kairouz et al., ‘Advances and Open Problems in Federated Learning’. arXiv, Mar. 08, 2021. Letzter Zugriff 9. Februar 2024 [Online]. http://arxiv.org/abs/1912.04977
[34] Franhofer IPA, ‘Fehler beim Schweißen: Schnell und automatisch erkannt’, Fraunhofer-Institut für Produktionstechnik und Automatisierung IPA. Letzter Zugriff 27. Februar 2024 [Online]. https://www.ipa.fraunhofer.de/de/presse/presseinformationen/fehler-beimschweissen-schnell-und-automatisch-erkannt.html.
[35] M. Kuehne-Schlinkert, K. Schmidt, E. Schwulera, B. Scharinger, T. Blumauer-Hiessl, und T. Kaufmann, ‘Overcoming the data deadlock - Federated Learning in Industry: Challenges, experiences, and take-aways from a real-world implementation of federated learning in electronics manufacturing.’, 2023.
[36] Y. Kim, P. Wang, und L. Mihaylova, ‘Structural Recurrent Neural Network for Traffic Speed Prediction’, no. arXiv:1902.06506. arXiv, Feb. 18, 2019. Letzter Zugriff 28. Januar 2024 [Online]. http://arxiv.org/abs/1902.06506.
[37] C. Latz, V. Vasileva, und M. A. Wimmer, ‘Supporting Smart Mobility in Smart Cities Through Autonomous Driving Buses: A Comparative Analysis’, in Electronic Government, vol. 13391, M. Janssen, C. Csáki, I. Lindgren, E. Loukis, U. Melin, G. Viale Pereira, M. P. Rodríguez Bolívar, and E. Tambouris, Eds., in Lecture Notes in Computer Science, vol. 13391. , Cham: Springer International Publishing, 2022, S. 479–496. doi: 10.1007/978-3-031-15086-9_31.
[38] Hochbahn, ‘Autonome On-Demand-Shuttles – Wie das Projekt ALIKE mit autonomen Kleinbussen den ÖPNV ergänzen soll’. Letzter Zugriff 27. Februar 2024 [Online]. https://www.hochbahn.de/de/projekte/autonome-on-demand-shuttles.
[39] K. Bonawitz et al., ‘Towards Federated Learning at Scale: System Design’, no.arXiv:1902.01046. arXiv, März 22, 2019. Letzter Zugriff 28. Januar 2024 [Online]. http://arxiv.org/abs/1902.01046.
[40] C. Niu et al., ‘Billion-scale federated learning on mobile clients: a submodel design with tunable privacy’, in Proceedings of the 26th Annual International Conference on Mobile Computing and Networking, London United Kingdom: ACM, Sep. 2020, S. 1–14. doi: 10.1145/3372224.3419188.
[41] L. Zhu et al., ‘PockEngine: Sparse and Efficient Fine-tuning in a Pocket’, in 56th Annual IEEE/ACM International Symposium on Microarchitecture, Okt. 2023, S. 1381–1394. doi: 10.1145/3613424.3614307.
[42] J. Weng, J. Weng, J. Zhang, M. Li, Y. Zhang, und W. Luo, ‘DeepChain: Auditable and Privacy-Preserving Deep Learning with Blockchain-based Incentive’, IEEE Trans. Dependable Secure Comput., S. 1–1, 2019, doi: 10.1109/TDSC.2019.2952332.

Mediathek

#11: Hannah Lim über Legal Technology in Südostasien
Hannah identifiziert als Head of Rule of Law and Emerging Markets bei LexisNexis in Singapur Bereiche, in denen die Firma mittels Technologie Rechtsstaatlichkeit unterstützen kann.
Jetzt lesen
#6: Lee San Natalie Pang über die Datenschutzregulierung DSGVO und ihren Einfluss auf Südostasien
Für die letzte Folge unseres ersten Themenbereiches „Datenschutz“ blicken mit Datenschutz-Expertin Dr. Lee San Natalie Pang auf den Südosten Asiens.
Jetzt lesen
#5: Ridwan Oloyede über die DSGVO und ihren Einfluss auf die Gesetzgebung in Afrika
Ridwan Oloyede ist Mitbegründer des nigerianischen Start-ups Tech Hive Advisory, das Unternehmen hilft, durch zuverlässige & effiziente Anwendung von Technologie besser zu werden.
Jetzt lesen
#4: Nadim Gemayel über die DSGVO und ihren Einfluss auf die Gesetzgebung im Nahen Osten
Nadim Gemayel ist Politiker und Anwalt und pendelt zwischen dem Libanon und Katar hin- und her. Er war von 2009 bis 2020 Mitglied des libanesischen Parlaments.
Jetzt lesen
#3: Eduardo Magrani über Datenschutz in Lateinamerika
Mit Eduardo Magrani sprechen wir über die DSGVO und ihren Einfluss auf die lateinamerikanische und vor allen die brasilianische Gesetzgebung.
Jetzt lesen
#2: Ioana Stupariu über den Einfluss der DSGVO in Südosteuropa
Ioana Stupariu berät kleine und mittelständische Start-ups in Südosteuropa bei der Implementierung von Datenschutzrichtlinien. Und sie forscht zu Datenschutz & Privacy.
Jetzt lesen